

【AWS】知識ゼロから理解するRDS超入門
AWSのデータベースサービス「Amazon RDS」を初心者にもわかるように解説します。未経験には難しいMultiAZ構成やレプリケーションは、マスター/スレ...
2018-04-16 21:22 2018-05-29 20:58

「プログラミング未経験の私がPythonの機械学習で手書き文字の識別を行うまで」というテーマで、機械学習の知識ゼロな非エンジニアの人が途中で挫折することないように、わかりやすく伝えることを意識して話していきます。
この記事を読めば、あなたもきっと「ニューラルネットワークとは、何か」を人に伝えらることができるくらい理解することができるはずです。
はじめまして、ゆざです。株式会社PLANのインターン生です。まずは、本題に入る前にそもそもなぜ未経験者の私がプログラミングを始めたのかをお話したいと思います。
最初はエンジニアになりたかったからではなく、漠然と「企業で働くってどんなこと?」「ITベンチャー企業とは?」を実際に働きながら知りたいと思い、インターンシップに応募したのが、株式会社PLANと出会ったきっかけです。
株式会社PLANはWebメディアサイトが最も大きい事業だったので、最初はライターとしてメディアの記事を書いたり、記事の大きな枠組みである専門ページを作る側のエディターとして、構造表と呼ばれるWebページの設計図を作る仕事をしていました。
新しいことをするのは、とても楽しくてインターンとしての仕事にやりがいを感じていました。
しかし、半年後、自分の将来について改めて考えた時に、「自分の考えたアイディアが自分の手で実装できるのは、エンジニアだけではないのか。自分はそんな人になりたい。」と思い、プログラミングに対してすごく興味を持ち、独学でPythonや機械学習の勉強を始めました。
そんな中、ちょうど同じタイミングに株式会社PLANのCTOであるみやびさんから「一緒にエンジニアのほうでインターンやってみない?」と声をかけていただき、私にとって絶好のチャンスと思い、二つ返事でお話を受けさせてもらいました。
そして、晴れて私のエンジニアとして道がスタートしました。本当に運と縁に恵まれました。(※ただし、この時点ではPythonとPHPの違いもろくにわからない状態。笑)
まずはじめに作ったのは、Pythonを使って機械学習で0から9の手書き文字を認識する識別器を作りました。
これは、MNIST(エムニスト:Mixed National Institute of Standards and Technology database)と呼ばれる0から9の手書き文字が無数に含んだデータセットを用いて行う機械学習の基本的な学習モデルです。
簡単に言うと、手で書かれた0-9の10コの数字から1つ、例えば「8」を作成したモデルに入ると、「あなたが書いた数字は"8"です。」といった判別結果を返してくれます。私が作ったモデルは、MNISTを用いて識別率96%を得ることができました。
全くコードが書けない状態から自分の手で書いた数字を入力すると、正しい値が返ってくるということに私はとても感動を覚えました。皆さんにも是非そのような経験をこの記事を読んで、手を動かすことによって得られたらいいなと思っています。
では、機械学習をプログラミングで実装する前は、機械学習・ディープラーニング・AIの基礎である最も重要なニューラルネットワークというアルゴリズムの手法について説明していきます。
ココでは、高校数学の知識が少し必要になってきますのが、もし途中で完全に理解できなくてもスルーしてください。機械学習の権威であるスタンフォード大学のAndrew Ng教授も細かな理論ではなく、大枠で理解することが最も大切であると述べていますので安心して下さい。
ニューラルネットワーク(neural network)とは、人間の脳内にある神経細胞(ニューロン)とそのつながりを計算機上のシミュレーションによって、表現することを目指した数学的なモデルのことです。
このモデルは、入力層・隠れ層・出力層という3つの階層に分かれてます。そして、重み(W)がそのニューロン間のつながりの強さを示します。
1つ1つのニューロンは単純な仕組みですが、それを無数に組み合わせて、この重みを変更することによって、複雑な関数の近似が行うことができます。
ココまでが一般的なニューラルネットワークの解説ですが、これで理解できた人は、かなりの天才です。
99.9%の方が何のことかさっぱりだと思いますし、むしろそれで構わないので安心して下さい。それでは、次にもっと簡単な例を挙げて、ニューラルネットワークの本質に迫っていきます。
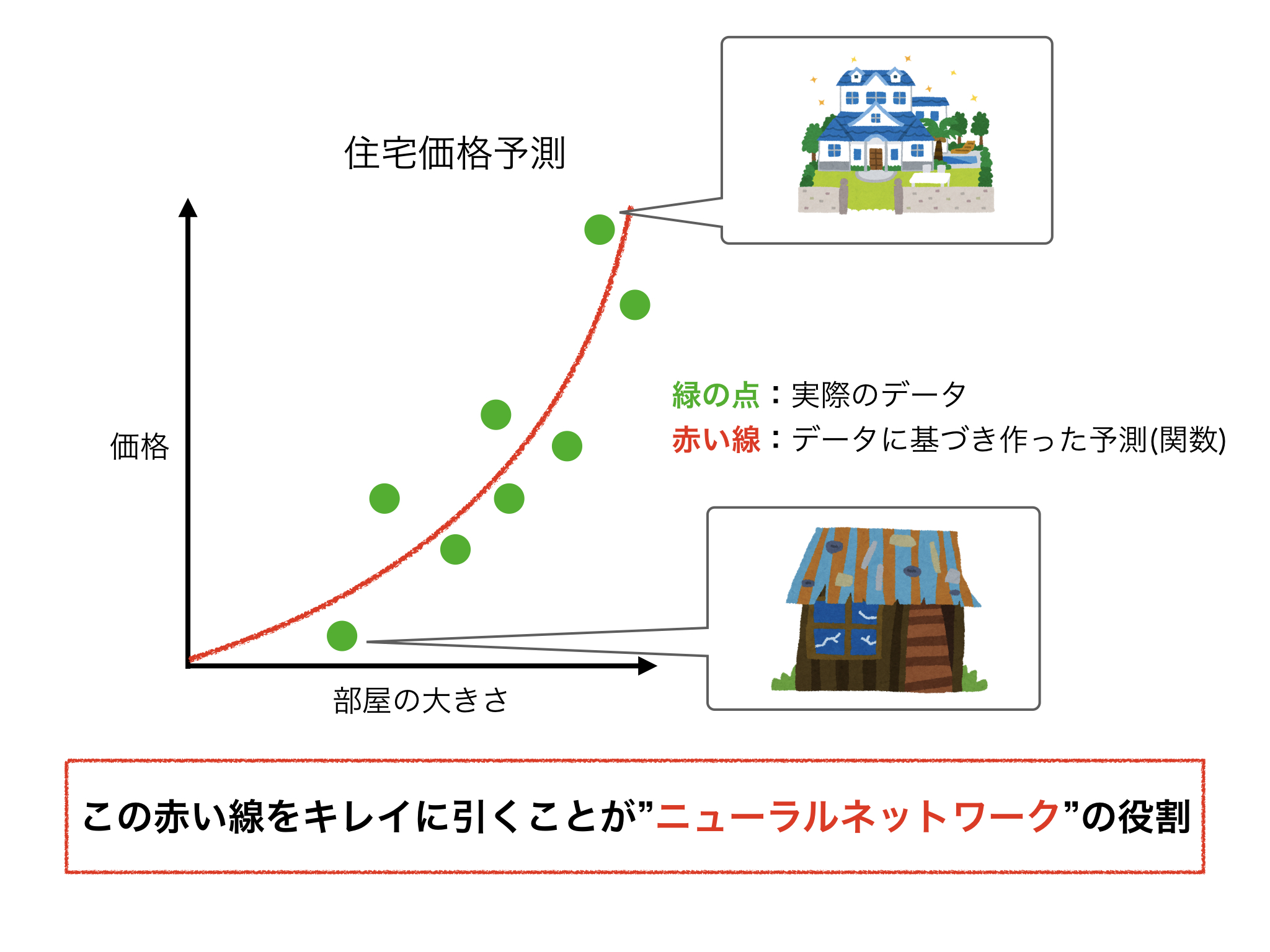
上記のグラフは横軸を部屋の大きさ、縦軸を住宅価格としたものです。そして、緑の点が実際のデータです。グラフの左下の点は、部屋が小さく価格が安い物件を表しており、右上の点は、部屋が大きくて価格が高い物件を表しています。
この緑の点(実際のデータ)に基づいて住宅価格を予想するための赤い線をキレイに引くことがニューラルネットワークの役割であり、本質です。
次にもっと多くのデータから住宅価格の予測を行っていきます。バリアフリー・間取り・立地条件・築年数・コンビニ/学校が近いをいう5つのデータを使います。
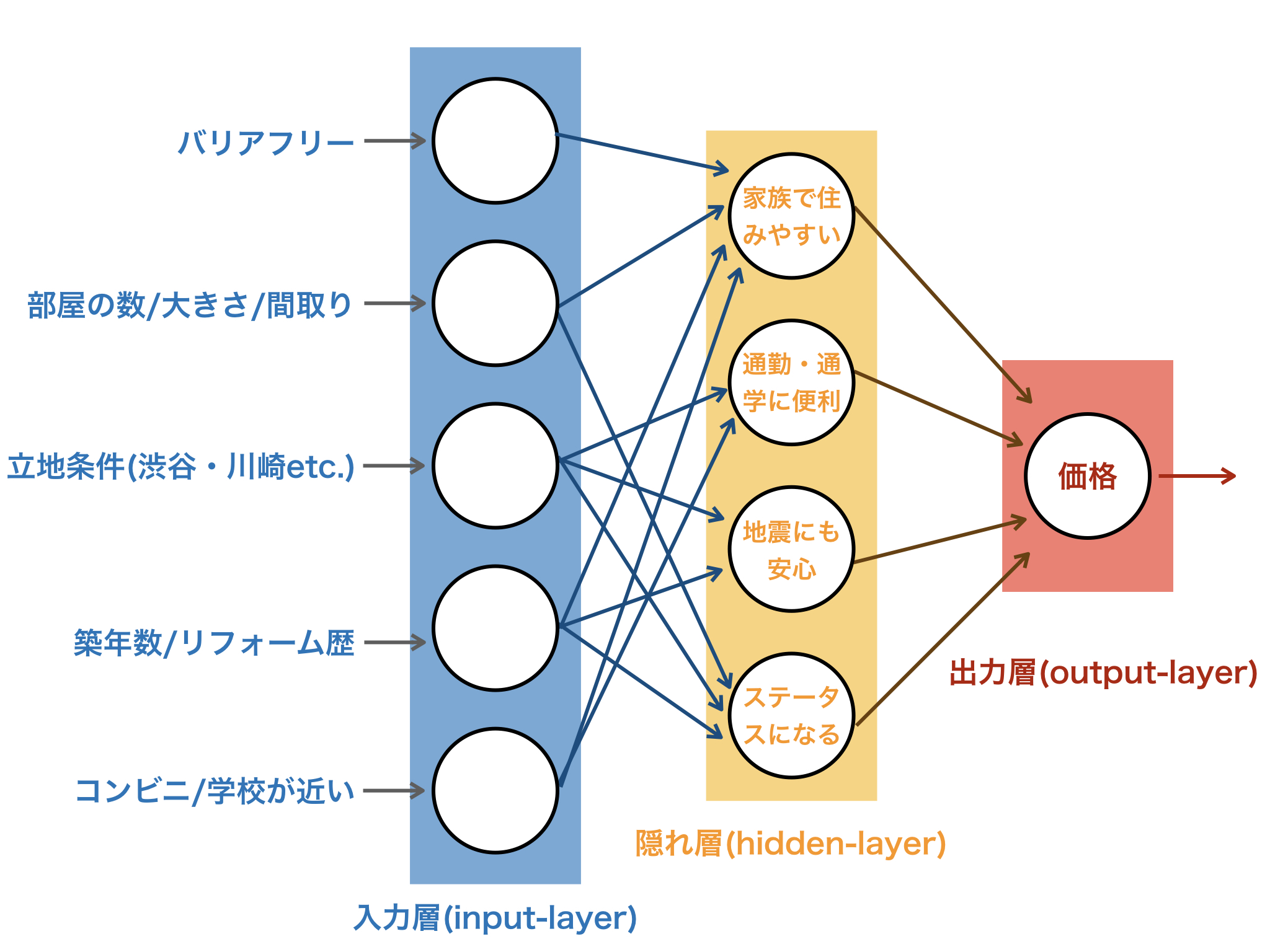
ここから、バリアフリーで部屋の数が豊富であるなら、家族で住みやすいということがわかったり、立地条件が交通便がいい場所なら、通勤・通学に便利で、新築で耐震工事がさせていて地盤の強い地域にあれば、地震にも安心といったように、さまざまな要素がデータから読み取れます。
そして、そのような要素を総合的に評価することによって住宅価格が決定します。
ニューラルネットワークも同様でデータをインプットして、そこから特徴を抽出して価格を予測することができます。
さらに、ニューラルネットワークには、中間にある隠れ層(hidden-layer)の要素(家族で住みやすいetc.)は自ら発見するため、こちらで見つける必要はありません。
ここまでの話が理解できれば、ニューラルネットワークの基本的な役割を理解したと言っても過言ではありません。それでは、次により実践的な例を踏まえてニューラルネットの構造について解説していきます。
イメージしてほしいのは、0から9の手書き文字を認識してその数字を当てる判別装置です。
この判別装置が数字を当てるまでには、
という段階を踏みます。隠れ層では行列計算と活性化関数を用いて特徴量を抽出します。
まずは、入力層へ手書き文字の画像をインプットします。
手書き文字のデータは、28*28pixelのグレースケールの画像(1つのpixel値は0-255の値で示す)で、この画像を入力層に入れるには、28*28pixelの正方形の画像をバラバラにしなければいけません。そのため、画像を28*28=748個の縦長のpixelの列に変換します。
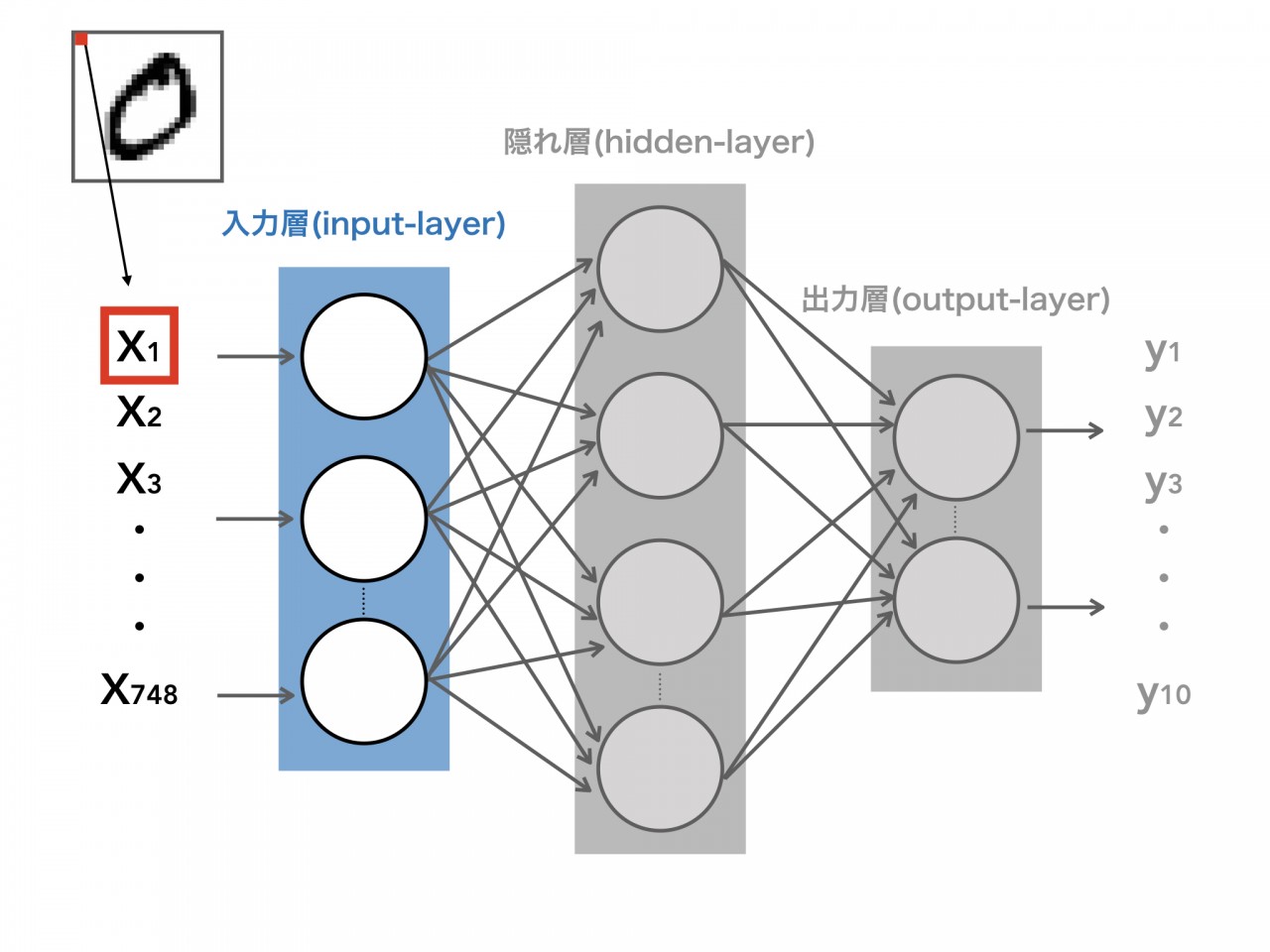
上の図の左上にある画像の赤いpixelをx1とおくと、784個すべてのpixelをx2,x3,x4,...,x748といったような値に置き換えることができます。
そして、次に入力層から隠れ層へデータが伝播されます。入力値xは、このニューロン(白マル)間の繋がりの強さを示す重みWと掛け合わせれ、伝播します。
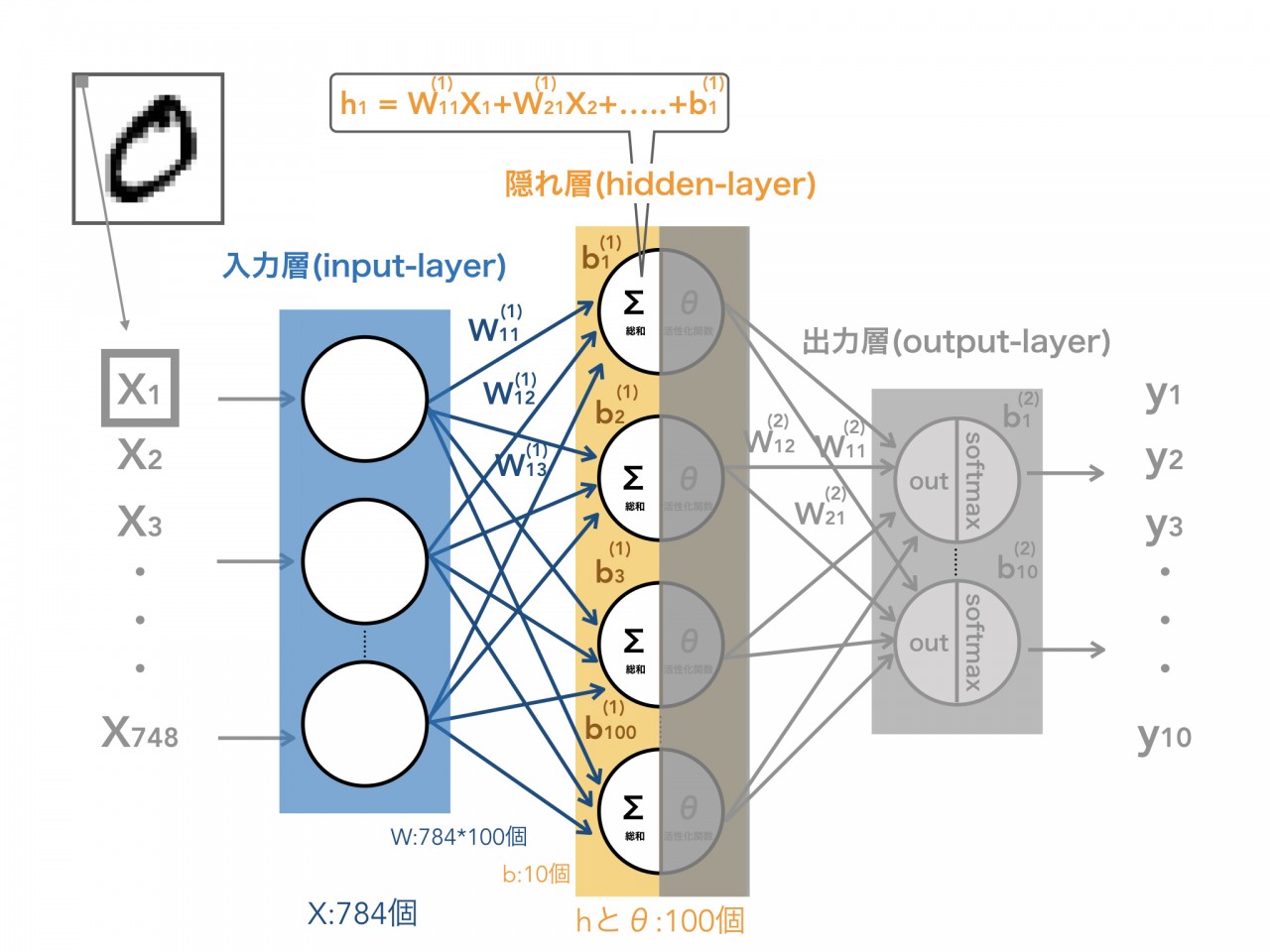
入力層にある1つのニューロンは、隠れ層にある全てのニューロン(今回は100個)に繋がっており、全てのxに対してWを掛け合わせます。
つまり、1つの隠れ層には入力層のニューロン全て(784個)からの繋がりがあり、そして、Wとxが掛け合わさせた784つの値の合計とバイアスbを加えて、hという隠れ層での値を生み出します(上の図の中央上部)。
バイアスbは、よりデータにばらつきを加える役割として使用します。
しかし、このままのモデルでは、h=Wx+bという直線(線形)だけしか表すことが出なくなってしまい、表現できるモデル(関数)が少ないです。
そのため、活性化関数と呼ばれる関数にこのhを代入します。
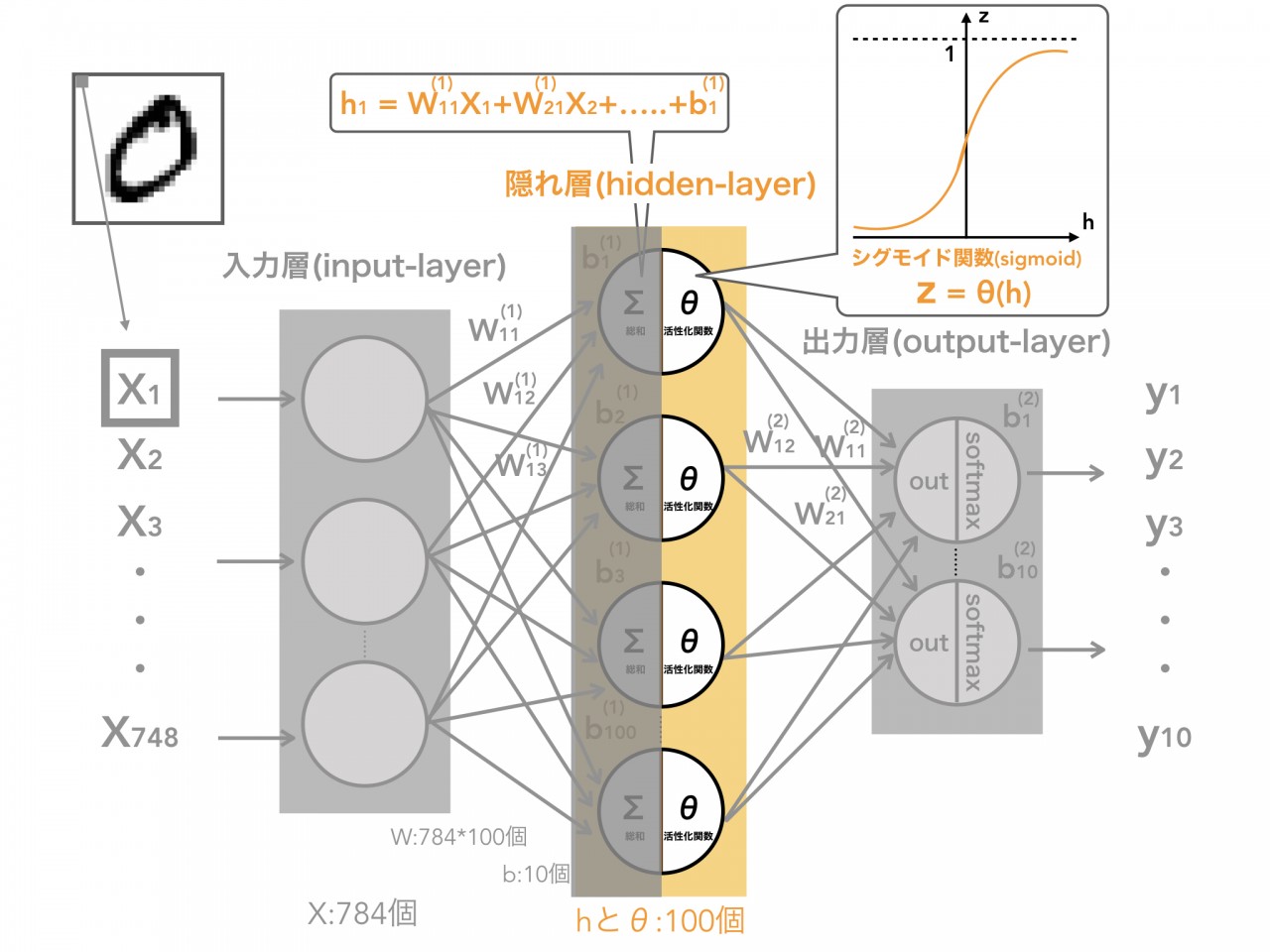
今回使用する関数は、シグモイド関数といって代入した値は0から1の間に収まるような値にしてくれる活性化関数です(z=θ(h):θはシグモイド関数を示す)。
このステップにより、ニューラルネットワークは自ら特徴を抽出して、複雑な関数近似を表現できるようになります。
次は、隠れ層から出力層への伝播です。
これは、先程の処理と同様にWとzが掛け合わさせた値の合計にバイアスbを加えることでoutという値を生み出します(下の図)。
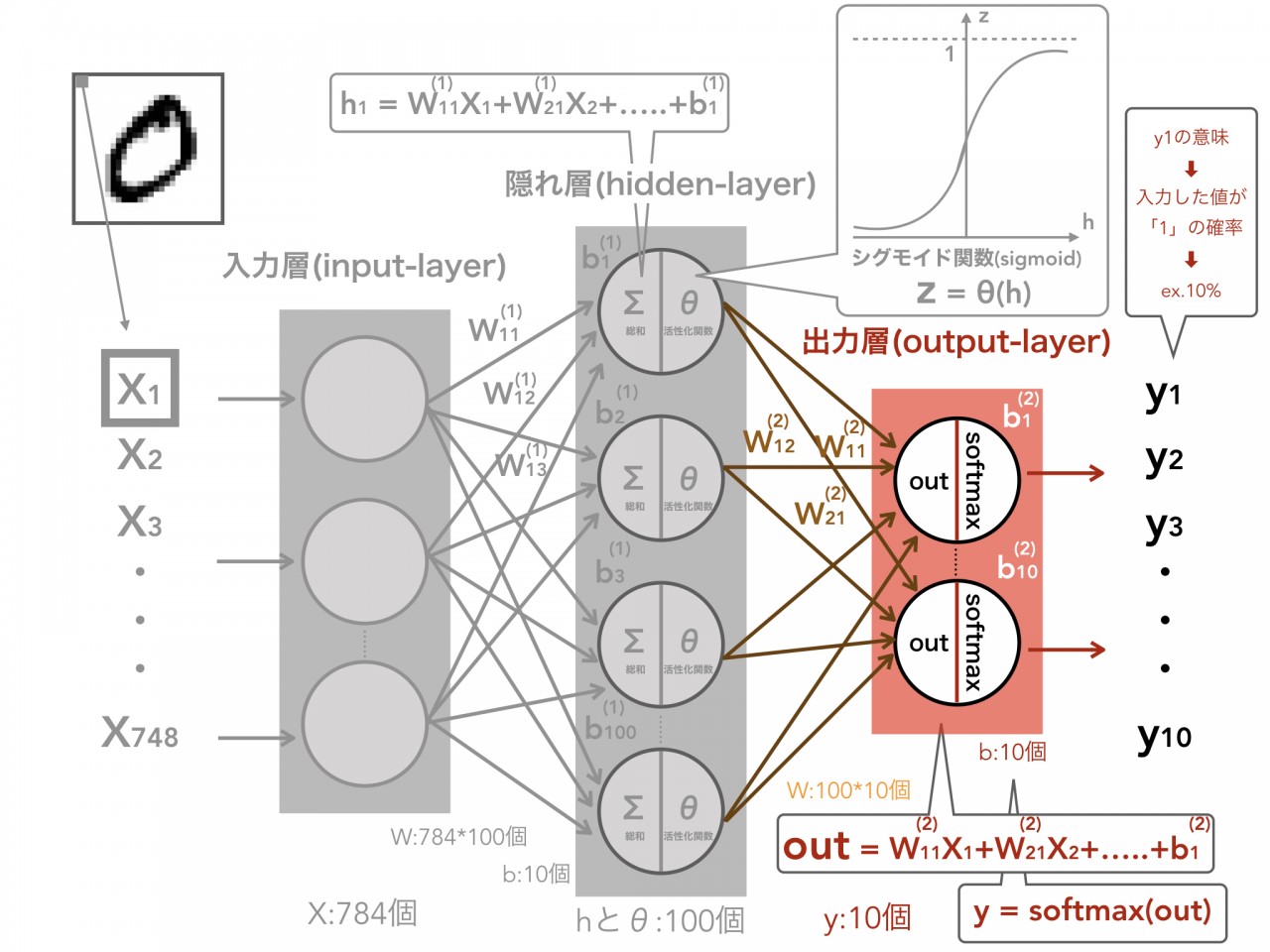
この出力層では、0から9を表現するために10つのアウトプット、つまりy1からy10が最終的な出力としてあります。
y1は入力層に入力した画像が「1」である確率を示しており、y2は「2」である確率を表しています。
したがって、y1からy10を全て足した値は1(0-9の確率を全て合わせて100%)である必要あるため、そのような値になるように上手くoutを調節する必要があります。
その役割として、ソフトマックス関数(softmax)と呼ばれる関数を使用します。
ソフトマックス関数は、出力を0-1の値に落とし込み、そして、出力された値の合計が1となるように値を返してくれます。
よって、最終的にほしい出力値yは、outをソフトマックス関数に入れることで求めます。これで、y1からy10の中で最も確率が高い値を予測値として得ることができました。
ここまでの内容をまとめると、以下のようになります。
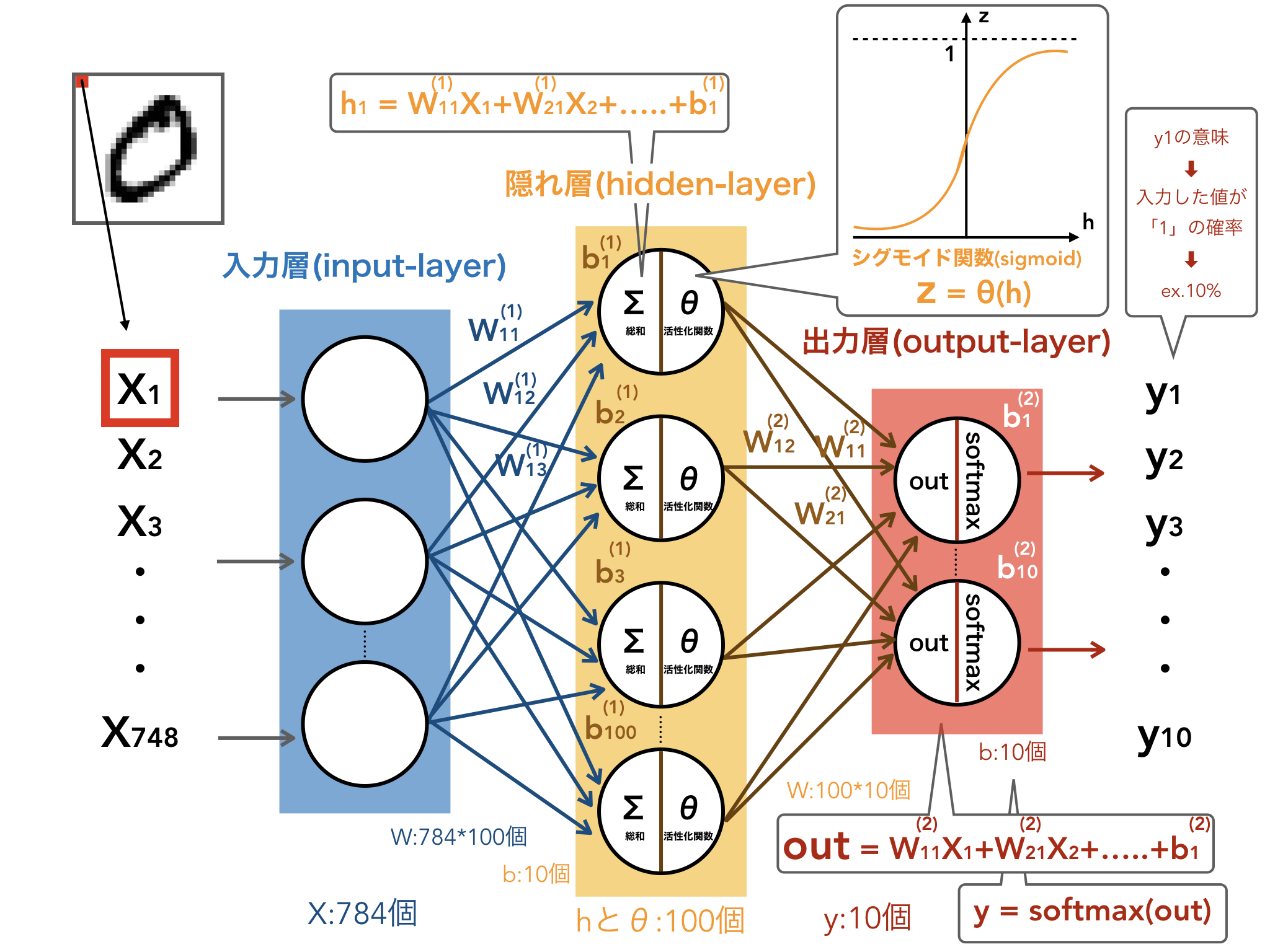
一度に全てをイメージすることは大変かもしれませんが、処理を分割しながら考えることで理解しやすくなるはずです。1つ1つやっている処理自体は決して難しくないので、どのような処理が行われているかをいくつかに分けて理解していきましょう。
ここまでニューラルネットワークの構造について説明してきましたが、このままでは、まだ正確な予測をすることができません。なぜなら、まだこのモデルは学習を行えていないからです。
そのために、次はニューラルネットワークが「どのように学習するのか」、「どうやって予測する精度をあげていくのか」についてお話します。
結論から言うと、モデルの精度を高めるためには、予測した値と実際の正しい値との誤差を最も小さくすればいいです。
では、どのようにその誤差を小さくしていくのでしょうか。それは、誤差を最小にするように重みWとバイアスbを更新していきます。
まずは、予測値と正解ラベルとの誤差を評価するために損失関数を用います(下の図の中央部)。
これは、誤差が大きくなると値は多くなり、小さくなると値も小さくなるという特性を持っている便利な関数です。
ここでの細かい数学的な理解は、ここでは必要ありません。肝心なのは、この関数をどうやって最小にするかということです。
この関数は、Wとbを更新する値、変数として、実際に下の図の左上部のように3次元的に考えることができます。
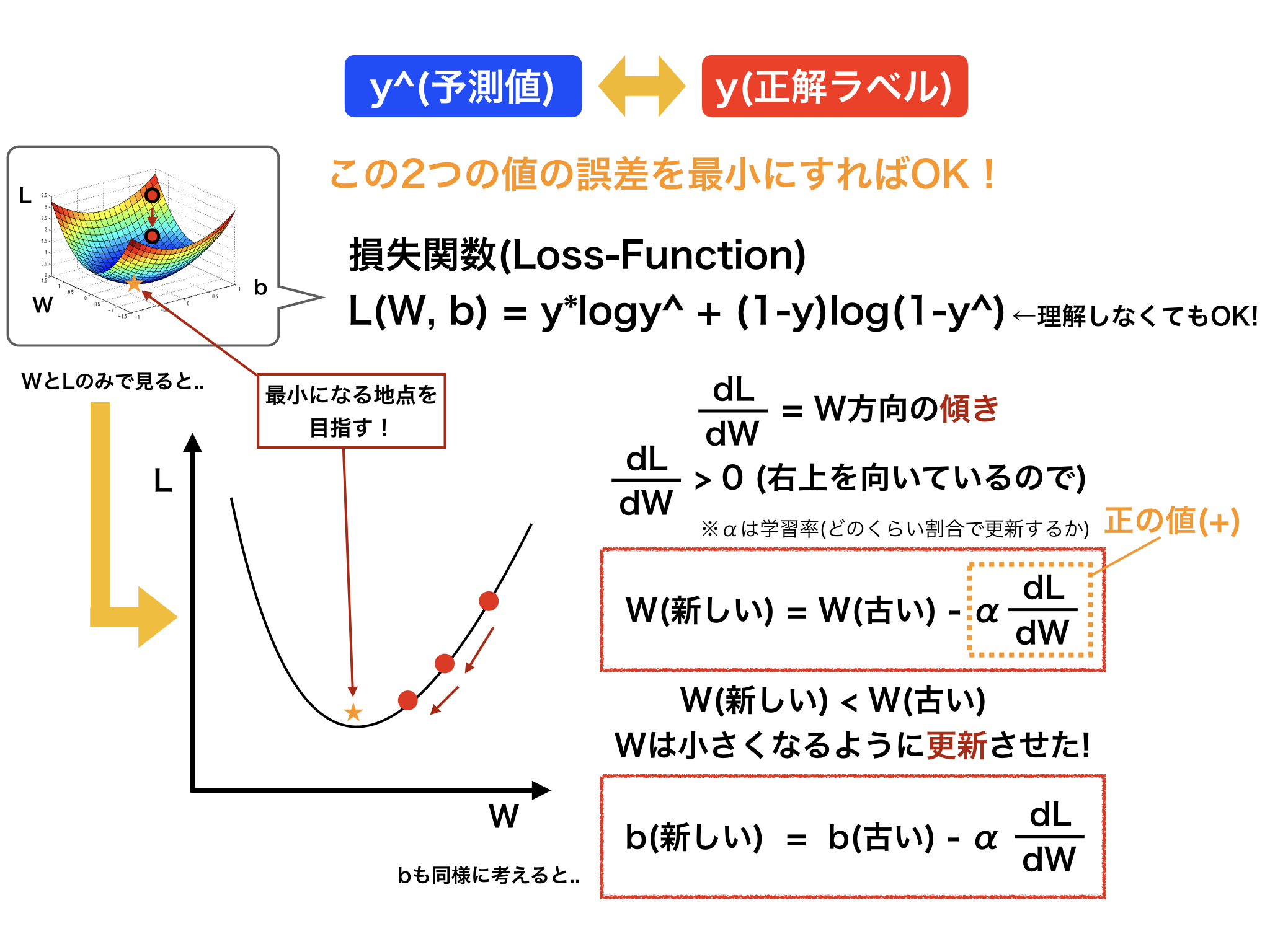
スタートでは、この図の赤い点のようにL(誤差)が高い位置にありますが、この赤い点をコロコロとWとbを更新することで動かしていき、最終的に星の描かれている最も低い位置、つまり誤差の最小となる地点を目指していきます。
実際に計算をして、それを検証するには、3次元的に考えていくと理解が難しくなるので、ここでWとLのみの2次元的に見ていきます。
これにより、上の図のように放物線のようなグラフがみられます。それでは、どのようにこの赤い点を動かしていくかを少しだけ数学的な観点から説明していきます。
そこで重要になるのが「微分」です。微分と聞いただけでアレルギーが出る人がいるかもしれませんが、微分の本質はグラフの傾きを表しているだけです。なので、〇〇を✕✕で微分するといったらその地点でのグラフの傾きに注目してください。
まず、スタート地点でどれだけグラフが傾いているかを示すため、WでLを微分した値を出します(dL/dWはWでLを微分するという意味)。この地点では、グラフは右上向きを向いているので、dL/dWは正の値となります。
そして、Wを新しい値に更新するためにW(新しい)=W(古い)-α*dL/dWという計算を行います。αは学習率を表しており、どのくらいの割合で更新をするかを示してます。つまり、αは任意の正の値が入り、dL/dWも正の値なのでWから正の値を引いたことになり、この計算ではW(新しい)はW(古い)により小さな値に更新させました。
このことによって、グラフの赤い点も左下に移動しました。つまり、誤差を小さくなるようにWが修正させたことが、ご理解いただけたのではないでしょうか。これを繰り替えることによって、誤差が最小になる地点に到達します。
今の説明では、重みWだけだったのですが、バイアスbも同様にして更新していくことができるので、b(新しい)=b(古い)-α*dL/dbという式で更新を行うことができます。
ここまで、理解するまでにかなりの労力を要したと思いますが、これが軸となるニューラルネットワークによるモデルの学習プロセスです。
この段階では、1つのデータにおいてW,bに対する誤差を最小にする動きでしたが、実際は複数のデータを用いるので、次はそこだけ簡単に説明していきます。
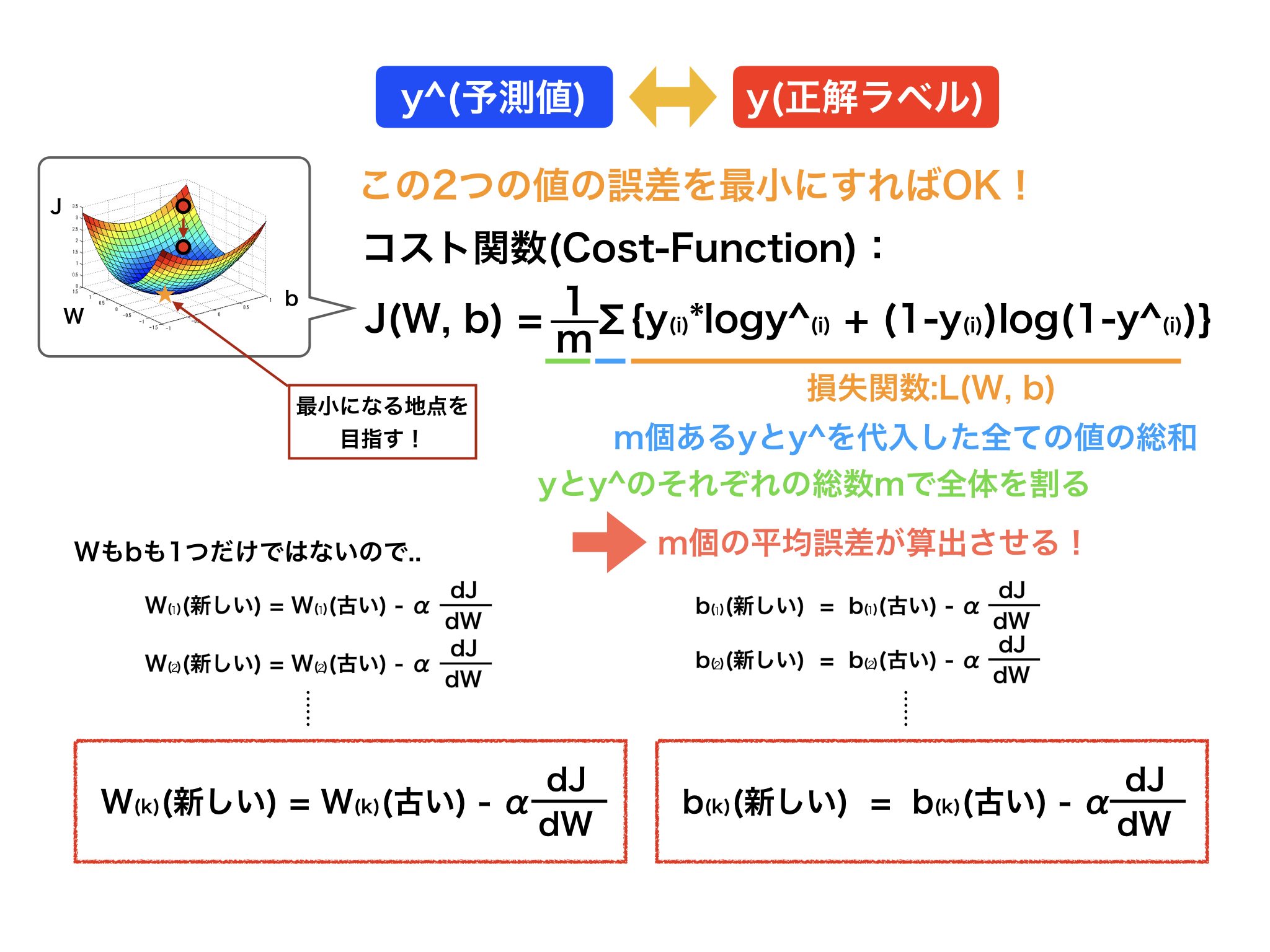
先程の説明との違いは、損失関数をベースとしたコスト関数を使用するという点だけです。
コスト関数とは、下の図に書かれている数式にあるようにデータの総数m個分の損失関数(オレンジの部分)を足して(青の部分)、その値をmで割る(緑の部分)、要はデータ1つ分の誤差平均値を計算します。
一見難しそうですが、先程の損失関数との違いは、データを1つ使用しているか、複数のデータを使用して平均値を使用しているかだけです。
なので、あまり難しく考えすぎないで下さい。もし、コスト関数を使ったとしてのW,bの更新する方法は全く同じで、出てくる値が配列として得られるか、単一の数字として得られるかの違いのみです。
そして、最後に1つだけ伝えたいのが、誤差は後ろから順番に更新させていくということです。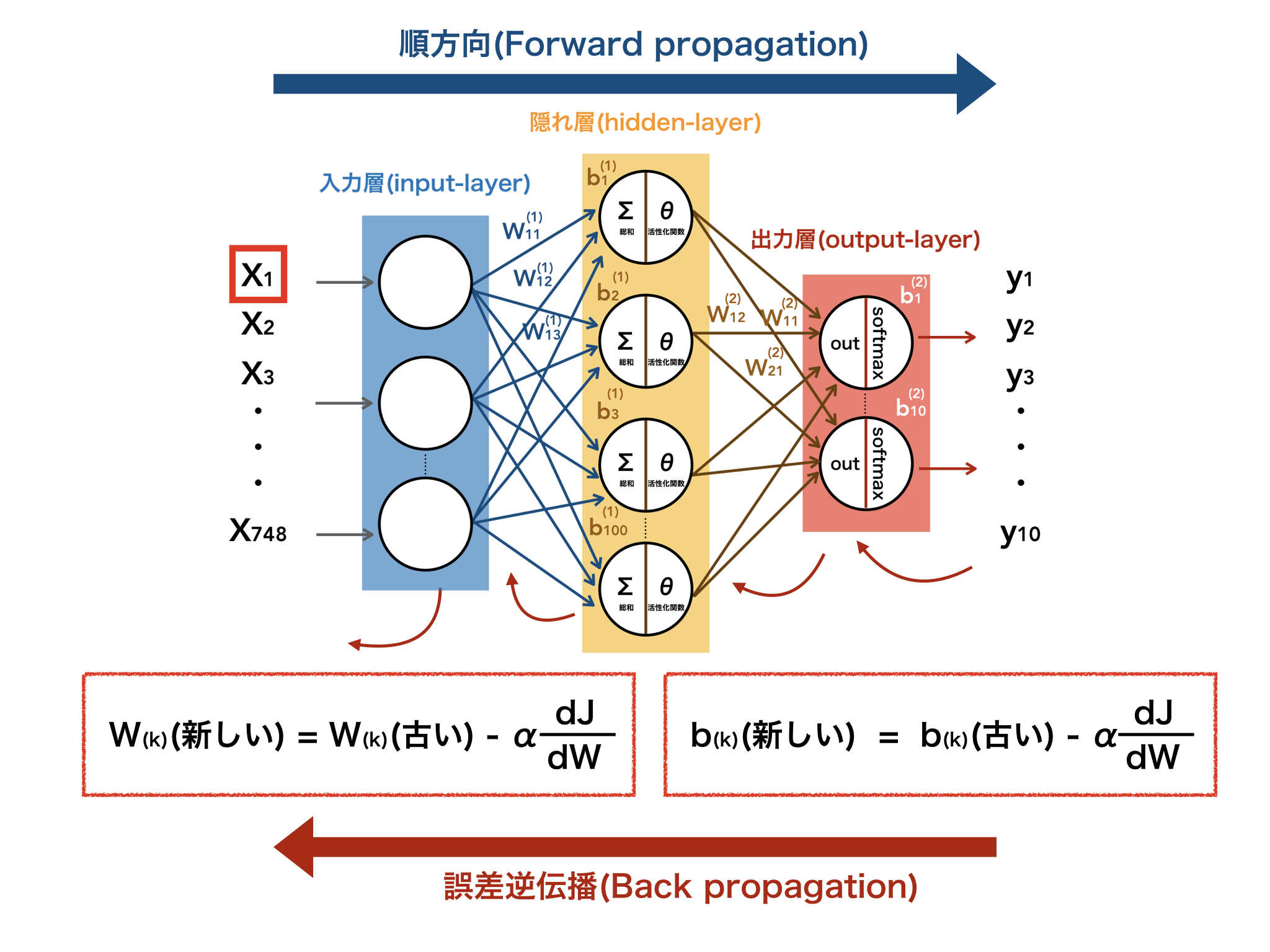
順方向で入力させたデータは、ニューロンの繋がりを通って入力層・隠れ層・出力層を経て、予測値としてはき出されます。
その予測をより精度を高めるために、後ろから順番にW,bを先程の示した数式を使って更新していくという流れです。
この後ろから前に戻ってくる流れのことを誤差逆伝播と呼び、これを繰り替えることによって精度の高い予測が実現します。
以上が、ニューラルネットワークの仕組みです。
今回は、「プログラミング未経験の私がPythonの機械学習で手書き文字の識別を行うまで」の前半として機械学習・AIを理解するために必要なニューラルネットワークの基礎知識をお伝えしました。
ここまで、私の拙いはじめての記事を読んでいただき本当にありがとうございました。
この記事を読んで少しでもニューラルネットワークとは何かを理解する手助けになれてたら幸いです。以下に今回の記事を簡単にまとめます。
次回は、より実践的に私が書いたコードを見ながら、Pythonによる機械学習で手書き文字(MNIST)識別について解説していきます。
>>後半:MNIST実行環境の準備から手書き文字識別までを徹底解説はコチラ
また、AnacondaでのTensorFlow環境構築と基礎的な使い方を先に読んでおくと基本的なライブラリの使い方がわかるのでコードの理解が早いかもしれません。
学生Webエンジニア PLANインターン生 PHP Laravel Python HTML CSS JS
【名前】 "ゆざ"
【関連】 株式会社PLAN / MIYABI Lab / Tmeet(twitterユーザーマッチングサービス) /
【MIYABI Lab運営】23歳/同期がト◯タやMicr◯softに就職する中、ベンチャーに未経験でWebエンジニアになるのを選んだ脳科学専攻の理系院生◆人見知り日本縦断◆機械学習/Web歴5ヶ月
【AWS】知識ゼロから理解するRDS超入門
AWSのデータベースサービス「Amazon RDS」を初心者にもわかるように解説します。未経験には難しいMultiAZ構成やレプリケーションは、マスター/スレ...

【AWS】Auto Scalingする前に知っておくべき7つのこと
Amazon EC2 Auto Scaling(オートスケール)を使用すると、CPU使用率等に応じてEC2の台数を自動的に増減できます。ここでは、初心者の持つ疑問を通し...

WordPressの基本構造を理解してオリジナルテーマを作ろう(後半)
WordPressのテーマを自作するために必要なテンプレートファイル(functions.phpやstyle.css)の役割やファイル構造を理解して、どのようにオリジナ...

WordPressの基本構造を理解してオリジナルテーマを作ろう(前半)
WordPressのテーマを自作するために必要なテンプレートファイル(functions.phpやfront-page.php)の役割やファイル構造を理解して、どのようにオ...

【Heroku入門】無料枠サーバーを24時間スリープさせない方法
フリープランのHerokuサーバーでは、30分以上アクセスがないと自動的にスリープしてしまいます。ここでは、Herokuサーバーを寝かせない方法につい...

【入門編】Laravelのディレクトリ構造とMVCの処理の流れを理解する
Laravel初心者が学習する際にわかりにくいLaravelのディレクトリ構造を具体的な例を交えて解説します。MVCの基本であるビュー、モデル、コントロー...

【初心者向け】PythonによるHeroku環境で簡単LINEBot開発
誰でも簡単にLINEBotをpythonを使ってHeroku環境で開発できる方法を解説します。ここでは、LINE Messaging APIを用いることでおうむ返しをするBot...

AWSでWebサーバー構築!踏み台サーバーでセキュアなネットワークを構築する(第5回)
連載の第5回です。メインEC2に対して直接SSH接続できる状態というのは、セキュリティの観点からあまり望ましくありません。MySQLやEBSが紐づいたメ...

AnacondaでのTensorFlow環境構築と基礎的な使い方
Anaconda(アナコンダ)のインストールからJupyter notebook(ジュピターノートブック)とTensorFlow(テンサーフロー)の基本的な使い方を初心者...

脱初心者!MNIST beginnerに隠れ層を加えたニューラルネット解説
TensorFlowのチュートリアルであるMNIST beginnerの応用して、隠れ層と活性化関数を加えたニューラルネットワークで手書き文字識別を解説します。...

AWSでWebサーバー構築!Apache2.4, PHP7, MySQLの導入と初期設定(第4回)
連載の第4回です。今回は作成したEC2インスタンスにWebサーバーとしての機能を持たせるため、Apache2.4のインストールおよびhttpd.conf等の各種設...

AWSでWebサーバー構築!EC2を作成してSSH接続する(第3回)
連載の第3回です。前回作成したVPC・サブネットにおいて、セキュリティーグループに保護されたEC2インスタンスの作成・設定およびSSH接続の確立ま...

初心者必読!MNIST実行環境の準備から手書き文字識別までを徹底解説!
Pythonによる機械学習をプログラミング初心者にもわかりやすいように、TensorFlowチュートリアルのMNIST beginnerを使って、手書き文字(MNIST)識別...

AWSでWebサーバー構築!専門用語の解説とVPC環境を構築する手順(第2回)
連載の第2回です。AWSにてVPCネットワークを構築してWebサーバーを設置・運用するためには、AWS内で利用される重要単語について正しく理解しておく...

知識ゼロで機械学習・AIを理解するために必要なニューラルネットワークの基礎知識
機械学習・AIを理解するために必要なニューラルネットワークの基礎について、これから機械学習を勉強したい人、プログラミング未経験の人にもわか...

Canvaで簡単におしゃれなアイキャッチ画像を作ろう!使い方を徹底解説!
PhotoshopやIllustratorを使えなくてもCanvaなら誰でも簡単におしゃれなアイキャッチ画像が作れます。豊富なデザインテンプレートを組み合わせるだ...

プレビュー機能付きの記事編集画面の作り方(Laravel5)
記事編集フォームにはプレビュー機能の実装が必須です。記事を保存する処理とプレビューを表示する処理を共存させるにあたり、ボタンをクリックし...

AWSでWebサーバー構築!VPC設計に必要なIPアドレスとサブネットの基礎知識(第1回)
連載の第1回です。AWSのVPCネットワークを設計して実際に構築するためには、IPアドレスの基礎を理解することが非常に大切です。EC2 Webサーバーを...

MIYABI Labホームページを製作しました
様々な理由でプログラミングの勉強を困難だと感じてしまっている方のお役に立てれば嬉しいです。これからも小さなWebサービスを作り続けていき、技...

ゆざ、株式会社PLANを卒業します。
2年間インターンとしてお世話になった株式会社PLANを卒業します。AWS,Laravel,Pythonなどの技術的なことだけではなく、エンジニアとして、社会人と...